SatMOC 2024
![]()
From Satellites to Solutions: Drought Monitoring with Google Earth Engine
- Registration: https://www.nesdis.noaa.gov/events/satellites-solutions-drought-monitoring-google-earth-engine
- Notebook: https://geemap.org/workshops/SatMOC_2024
- Earth Engine: https://earthengine.google.com
- Geemap: https://geemap.org
Introduction¶
This notebook is designed for the summer short course offered by the American Meteorological Society (AMS) Committee on Satellite Meteorology, Oceanography, and Climatology (SatMOC).
Description¶
Droughts pose a critical threat to water resources, agriculture, and ecosystems worldwide. This hands-on short course will teach you how to harness the power of Google Earth Engine (GEE) to monitor and analyze drought patterns. GEE's vast repository of satellite data and powerful cloud computing capabilities will streamline your drought research and decision-making.
In this short course, you will:
- Explore the fundamentals of remote sensing for drought monitoring.
- Learn to calculate and interpret key drought indices such as the Palmer Drought Severity Index (PDSI) and Standardized Precipitation Index (SPI).
- Master GEE coding techniques to process large geospatial datasets.
- Create dynamic visualizations that track the evolution of drought conditions over time.
- Develop tools to support local and regional drought management strategies.
Prerequisites¶
To use geemap and the Earth Engine Python API, you must register for an Earth Engine account and follow the instructions here to create a Cloud Project. Earth Engine is free for noncommercial and research use. To test whether you can use authenticate the Earth Engine Python API, please run this notebook on Google Colab.
It is recommended that attendees have a basic understanding of Python and Jupyter Notebook.
Familiarity with the Earth Engine JavaScript API is not required but will be helpful.
Attendees can use Google Colab to follow this short course without installing anything on their computer.
By the end of this short course, you will have the skills and resources to confidently integrate Google Earth Engine into your drought monitoring and decision-making workflows.
Agenda¶
This short course consists of six 30-minute sessions. During each hands-on session, the attendees will walk through Jupyter notebook examples on Google Colab. At the end of each session, they will complete a hands-on exercise to apply the knowledge they have learned in each session.
- Course introduction and software setup (30 mins)
- Introduction and location of short course materials
- Introduction to Earth Engine and geemap
- Google Colab and Earth Engine Python API authentication
- Using Earth Engine data (30 mins)
- Earth Engine data types
- Earth Engine Data Catalog
- Exercise: creating cloud-free imagery
- Visualizing Earth Engine data (30 mins)
- Geemap Inspector tool, plotting tool, interactive GUI for data visualization
- Legends, color bars, and labels
- Split-panel map and linked maps
- Timeseries inspector and time slider
- Exercise: visualizing timeseries precipitation and vegetation data
- Creating timelapse animations (30 mins)
- MODIS vegetation indices
- MODIS temperature data
- GOES satellite data
- Exercise: creating timelapse animations
- Drought monitoring (30 mins)
- Exploring drought datasets
- Creating drought timeseries animations
- Computing zonal statistics
- Creating interactive charts
- Exercise: visualizing drought data for a selected region
- Analyzing and visualizing precipitation data (30 mins)
- Exploring precipitation datasets
- Creating precipitation timeseries
- Calculating Standardized Precipitation Index (SPI)
- Exercise: calculating SPI for a selected region
Introduction to Earth Engine and geemap¶
Earth Engine is free for noncommercial and research use. For more than a decade, Earth Engine has enabled planetary-scale Earth data science and analysis by nonprofit organizations, research scientists, and other impact users.
With the launch of Earth Engine for commercial use, commercial customers will be charged for Earth Engine services. However, Earth Engine will remain free of charge for noncommercial use and research projects. Nonprofit organizations, academic institutions, educators, news media, Indigenous governments, and government researchers are eligible to use Earth Engine free of charge, just as they have done for over a decade.
The geemap Python package is built upon the Earth Engine Python API and open-source mapping libraries. It allows Earth Engine users to interactively manipulate, analyze, and visualize geospatial big data in a Jupyter environment. Since its creation in April 2020, geemap has received over 3,300 GitHub stars and is being used by over 2,700 projects on GitHub.
Google Colab and Earth Engine Python API authentication¶
![]()
Change Colab dark theme¶
Currently, ipywidgets does not work well with Colab dark theme. Some of the geemap widgets may not display properly in Colab dark theme.It is recommended that you change Colab to the light theme.

Install geemap¶
The geemap package is pre-installed in Google Colab and is updated to the latest minor or major release every few weeks. Some optional dependencies of geemap being used by this notebook are not pre-installed in Colab. Uncomment the following code block to install geemap and some optional dependencies.
# %pip install -U "geemap[workshop]"
Note that some geemap features may not work properly in the Google Colab environmennt. If you are familiar with Anaconda or Miniconda, it is recommended to create a new conda environment to install geemap and its optional dependencies on your local computer.
conda create -n gee python=3.11
conda activate gee
conda install -c conda-forge mamba
mamba install -c conda-forge geemap pygis
Import libraries¶
Import the earthengine-api and geemap.
import ee
import geemap
Authenticate and initialize Earth Engine¶
You will need to create a Google Cloud Project and enable the Earth Engine API for the project. You can find detailed instructions here.
ee.Authenticate()
ee.Initialize(project="YOUR-PROJECT-ID")
Creating interactive maps¶
Let's create an interactive map using the ipyleaflet plotting backend. The geemap.Map class inherits the ipyleaflet.Map class. Therefore, you can use the same syntax to create an interactive map as you would with ipyleaflet.Map.
m = geemap.Map()
To display it in a Jupyter notebook, simply ask for the object representation:
m
To customize the map, you can specify various keyword arguments, such as center ([lat, lon]), zoom, width, and height. The default width is 100%, which takes up the entire cell width of the Jupyter notebook. The height argument accepts a number or a string. If a number is provided, it represents the height of the map in pixels. If a string is provided, the string must be in the format of a number followed by px, e.g., 600px.
m = geemap.Map(center=[40, -100], zoom=4, height="600xp")
m
To hide a control, set control_name to False, e.g., draw_ctrl=False.
m = geemap.Map(data_ctrl=False, toolbar_ctrl=False, draw_ctrl=False)
m
Adding basemaps¶
There are several ways to add basemaps to a map. You can specify the basemap to use in the basemap keyword argument when creating the map. Alternatively, you can add basemap layers to the map using the add_basemap method. Geemap has hundreds of built-in basemaps available that can be easily added to the map with only one line of code.
Create a map by specifying the basemap to use as follows. For example, the Esri.WorldImagery basemap represents the Esri world imagery basemap.
m = geemap.Map(basemap="Esri.WorldImagery")
m
You can add as many basemaps as you like to the map. For example, the following code adds the OpenTopoMap basemap to the map above:
m.add_basemap("OpenTopoMap")
You can also change basemaps interactively using the basemap GUI.
m = geemap.Map()
m.add("basemap_selector")
m
Using Earth Engine data¶
Earth Engine data types¶
Earth Engine objects are server-side objects rather than client-side objects, which means that they are not stored locally on your computer. Similar to video streaming services (e.g., YouTube, Netflix, and Hulu), which store videos/movies on their servers, Earth Engine data are stored on the Earth Engine servers. We can stream geospatial data from Earth Engine on-the-fly without having to download the data just like we can watch videos from streaming services using a web browser without having to download the entire video to your computer.
- Image: the fundamental raster data type in Earth Engine.
- ImageCollection: a stack or time-series of images.
- Geometry: the fundamental vector data type in Earth Engine.
- Feature: a Geometry with attributes.
- FeatureCollection: a set of features.
Image¶
Raster data in Earth Engine are represented as Image objects. Images are composed of one or more bands and each band has its own name, data type, scale, mask and projection. Each image has metadata stored as a set of properties.
Loading Earth Engine images¶
image = ee.Image("USGS/SRTMGL1_003")
image
Visualizing Earth Engine images¶
m = geemap.Map(center=[21.79, 70.87], zoom=3)
image = ee.Image("USGS/SRTMGL1_003")
vis_params = {
"min": 0,
"max": 6000,
"palette": ["006633", "E5FFCC", "662A00", "D8D8D8", "F5F5F5"], # 'terrain'
}
m.add_layer(image, vis_params, "SRTM")
m
ImageCollection¶
An ImageCollection is a stack or sequence of images. An ImageCollection can be loaded by passing an Earth Engine asset ID into the ImageCollection constructor. You can find ImageCollection IDs in the Earth Engine Data Catalog.
Loading image collections¶
For example, to load the image collection of the Sentinel-2 surface reflectance:
collection = ee.ImageCollection("COPERNICUS/S2_SR")
Visualizing image collections¶
To visualize an Earth Engine ImageCollection, we need to convert an ImageCollection to an Image by compositing all the images in the collection to a single image representing, for example, the min, max, median, mean or standard deviation of the images. For example, to create a median value image from a collection, use the collection.median() method. Let's create a median image from the Sentinel-2 surface reflectance collection:
m = geemap.Map()
collection = (
ee.ImageCollection("COPERNICUS/S2_SR")
.filterDate("2023-01-01", "2024-01-01")
.filter(ee.Filter.lt("CLOUDY_PIXEL_PERCENTAGE", 5))
)
image = collection.median()
vis = {
"min": 0.0,
"max": 3000,
"bands": ["B4", "B3", "B2"],
}
m.set_center(-77.0054, 38.8974, 13)
m.add_layer(image, vis, "Sentinel-2")
m
FeatureCollection¶
A FeatureCollection is a collection of Features. A FeatureCollection is analogous to a GeoJSON FeatureCollection object, i.e., a collection of features with associated properties/attributes. Data contained in a shapefile can be represented as a FeatureCollection.
Loading feature collections¶
The Earth Engine Data Catalog hosts a variety of vector datasets (e.g,, US Census data, country boundaries, and more) as feature collections. You can find feature collection IDs by searching the data catalog. For example, to load the TIGER roads data by the U.S. Census Bureau:
m = geemap.Map()
fc = ee.FeatureCollection("TIGER/2016/Roads")
m.set_center(-73.9596, 40.7688, 12)
m.add_layer(fc, {}, "Census roads")
m
Filtering feature collections¶
m = geemap.Map()
states = ee.FeatureCollection("TIGER/2018/States")
fc = states.filter(ee.Filter.eq("NAME", "Tennessee"))
m.add_layer(fc, {}, "Tennessee")
m.center_object(fc, 7)
m
m = geemap.Map()
states = ee.FeatureCollection("TIGER/2018/States")
fc = states.filter(ee.Filter.inList("NAME", ["California", "Oregon", "Washington"]))
m.add_layer(fc, {}, "West Coast")
m.center_object(fc, 5)
m
region = m.user_roi
if region is None:
region = ee.Geometry.BBox(-88.40, 29.88, -77.90, 35.39)
fc = ee.FeatureCollection("TIGER/2018/States").filterBounds(region)
m.add_layer(fc, {}, "Southeastern U.S.")
m.center_object(fc, 6)
Visualizing feature collections¶
m = geemap.Map(center=[40, -100], zoom=4)
states = ee.FeatureCollection("TIGER/2018/States")
m.add_layer(states, {}, "US States")
m
m = geemap.Map(center=[40, -100], zoom=4)
states = ee.FeatureCollection("TIGER/2018/States")
style = {"color": "0000ffff", "width": 2, "lineType": "solid", "fillColor": "FF000080"}
m.add_layer(states.style(**style), {}, "US States")
m
m = geemap.Map(center=[40, -100], zoom=4)
states = ee.FeatureCollection("TIGER/2018/States")
vis_params = {
"color": "000000",
"colorOpacity": 1,
"pointSize": 3,
"pointShape": "circle",
"width": 2,
"lineType": "solid",
"fillColorOpacity": 0.66,
}
palette = ["006633", "E5FFCC", "662A00", "D8D8D8", "F5F5F5"]
m.add_styled_vector(
states, column="NAME", palette=palette, layer_name="Styled vector", **vis_params
)
m
Earth Engine Data Catalog¶
The Earth Engine Data Catalog hosts a variety of geospatial datasets. As of July 2024, the catalog contains over 1,100 datasets with a total size of over 100 petabytes. Some notable datasets include: Landsat, Sentinel, MODIS, NAIP, etc. For a complete list of datasets in CSV or JSON formats, see the Earth Engine Datasets List.
Searching for datasets¶
The Earth Engine Data Catalog is searchable. You can search datasets by name, keyword, or tag. For example, enter "elevation" in the search box will filter the catalog to show only datasets containing "elevation" in their name, description, or tags. 52 datasets are returned for this search query. Scroll down the list to find the NASA SRTM Digital Elevation 30m dataset. On each dataset page, you can find the following information, including Dataset Availability, Dataset Provider, Earth Engine Snippet, Tags, Description, Code Example, and more. One important piece of information is the Image/ImageCollection/FeatureCollection ID of each dataset, which is essential for accessing the dataset through the Earth Engine JavaScript or Python APIs.

m = geemap.Map()
m
m = geemap.Map()
dem = ee.Image("USGS/SRTMGL1_003")
vis_params = {
"min": 0,
"max": 4000,
"palette": ["006633", "E5FFCC", "662A00", "D8D8D8", "F5F5F5"],
}
m.add_layer(dem, vis_params, "SRTM DEM")
m
Exercise 1 - Creating cloud-free imagery¶
Create a cloud-free imagery of a selected US state for the year of 2023. You can use either Landsat 9 or Sentinel-2 imagery. Relevant Earth Engine assets:
- ee.FeatureCollection("TIGER/2018/States")
- ee.ImageCollection("COPERNICUS/S2_SR")
- ee.ImageCollection("LANDSAT/LC09/C02/T1_L2")
A sample map of cloud-free imagery for the state of Texas is shown below:

# Type your code here
m = geemap.Map(center=(40, -100), zoom=4)
dem = ee.Image("USGS/SRTMGL1_003")
landsat7 = ee.Image("LANDSAT/LE7_TOA_5YEAR/1999_2003").select(
["B1", "B2", "B3", "B4", "B5", "B7"]
)
states = ee.FeatureCollection("TIGER/2018/States")
vis_params = {
"min": 0,
"max": 4000,
"palette": ["006633", "E5FFCC", "662A00", "D8D8D8", "F5F5F5"],
}
m.add_layer(dem, vis_params, "SRTM DEM")
m.add_layer(
landsat7,
{"bands": ["B4", "B3", "B2"], "min": 20, "max": 200, "gamma": 2.0},
"Landsat 7",
)
m.add_layer(states, {}, "US States")
m.add("inspector")
m
Using the plotting tool¶
Plot spectral profiles of pixels using the plotting tool.
m = geemap.Map(center=[40, -100], zoom=4)
landsat7 = ee.Image("LANDSAT/LE7_TOA_5YEAR/1999_2003").select(
["B1", "B2", "B3", "B4", "B5", "B7"]
)
landsat_vis = {"bands": ["B4", "B3", "B2"], "gamma": 1.4}
m.add_layer(landsat7, landsat_vis, "Landsat")
hyperion = ee.ImageCollection("EO1/HYPERION").filter(
ee.Filter.date("2016-01-01", "2017-03-01")
)
hyperion_vis = {
"min": 1000.0,
"max": 14000.0,
"gamma": 2.5,
}
m.add_layer(hyperion, hyperion_vis, "Hyperion")
m.add_plot_gui()
m
Set plotting options for Landsat.
m.set_plot_options(add_marker_cluster=True, overlay=True)
Set plotting options for Hyperion.
m.set_plot_options(add_marker_cluster=True, plot_type="bar")
from geemap.legends import builtin_legends
for legend in builtin_legends:
print(legend)
Add NLCD WMS layer and legend to the map.
m = geemap.Map(center=[40, -100], zoom=4)
m.add_basemap("Esri.WorldImagery")
m.add_basemap("NLCD 2021 CONUS Land Cover")
m.add_legend(
title="NLCD Land Cover Type",
builtin_legend="NLCD",
max_width="100px",
height="455px",
)
m
Add NLCD Earth Engine layer and legend to the map.
m = geemap.Map(center=[40, -100], zoom=4)
m.add_basemap("Esri.WorldImagery")
nlcd = ee.Image("USGS/NLCD_RELEASES/2021_REL/NLCD/2021")
landcover = nlcd.select("landcover")
m.add_layer(landcover, {}, "NLCD Land Cover 2021")
m.add_legend(title="NLCD Land Cover Type", builtin_legend="NLCD", height="455px")
m
Custom legends¶
Add a custom legend by specifying a dictionary of colors and labels.
m = geemap.Map(center=[40, -100], zoom=4)
m.add_basemap("Esri.WorldImagery")
legend_dict = {
"11 Open Water": "466b9f",
"12 Perennial Ice/Snow": "d1def8",
"21 Developed, Open Space": "dec5c5",
"22 Developed, Low Intensity": "d99282",
"23 Developed, Medium Intensity": "eb0000",
"24 Developed High Intensity": "ab0000",
"31 Barren Land (Rock/Sand/Clay)": "b3ac9f",
"41 Deciduous Forest": "68ab5f",
"42 Evergreen Forest": "1c5f2c",
"43 Mixed Forest": "b5c58f",
"51 Dwarf Scrub": "af963c",
"52 Shrub/Scrub": "ccb879",
"71 Grassland/Herbaceous": "dfdfc2",
"72 Sedge/Herbaceous": "d1d182",
"73 Lichens": "a3cc51",
"74 Moss": "82ba9e",
"81 Pasture/Hay": "dcd939",
"82 Cultivated Crops": "ab6c28",
"90 Woody Wetlands": "b8d9eb",
"95 Emergent Herbaceous Wetlands": "6c9fb8",
}
nlcd = ee.Image("USGS/NLCD_RELEASES/2021_REL/NLCD/2021")
landcover = nlcd.select("landcover")
m.add_layer(landcover, {}, "NLCD Land Cover 2021")
m.add_legend(title="NLCD Land Cover Type", legend_dict=legend_dict)
m
Creating color bars¶
Add a horizontal color bar.
m = geemap.Map()
dem = ee.Image("USGS/SRTMGL1_003")
vis_params = {
"min": 0,
"max": 4000,
"palette": ["006633", "E5FFCC", "662A00", "D8D8D8", "F5F5F5"],
}
m.add_layer(dem, vis_params, "SRTM DEM")
m.add_colorbar(vis_params, label="Elevation (m)", layer_name="SRTM DEM")
m
Add a vertical color bar.
m.add_colorbar(
vis_params,
label="Elevation (m)",
layer_name="SRTM DEM",
orientation="vertical",
max_width="100px",
)
Make the color bar background transparent.
m.add_colorbar(
vis_params,
label="Elevation (m)",
layer_name="SRTM DEM",
orientation="vertical",
max_width="100px",
transparent_bg=True,
)
m = geemap.Map()
m.split_map(left_layer="Esri.WorldTopoMap", right_layer="OpenTopoMap")
m
Create a split map with Earth Engine layers.
m = geemap.Map(center=(40, -100), zoom=4, height=600)
nlcd_2001 = ee.Image("USGS/NLCD_RELEASES/2019_REL/NLCD/2001").select("landcover")
nlcd_2019 = ee.Image("USGS/NLCD_RELEASES/2021_REL/NLCD/2021").select("landcover")
left_layer = geemap.ee_tile_layer(nlcd_2001, {}, "NLCD 2001")
right_layer = geemap.ee_tile_layer(nlcd_2019, {}, "NLCD 2021")
m.split_map(left_layer, right_layer, left_label="NLCD 2001", right_label="NLCD 2021")
m
Linked maps¶
Create a 2x2 linked map for visualizing Sentinel-2 imagery with different band combinations. Note that this feature does not work properly with Colab. Panning one map would not pan other maps.
image = (
ee.ImageCollection("COPERNICUS/S2")
.filterDate("2018-09-01", "2018-09-30")
.map(lambda img: img.divide(10000))
.median()
)
vis_params = [
{"bands": ["B4", "B3", "B2"], "min": 0, "max": 0.3, "gamma": 1.3},
{"bands": ["B8", "B11", "B4"], "min": 0, "max": 0.3, "gamma": 1.3},
{"bands": ["B8", "B4", "B3"], "min": 0, "max": 0.3, "gamma": 1.3},
{"bands": ["B12", "B12", "B4"], "min": 0, "max": 0.3, "gamma": 1.3},
]
labels = [
"Natural Color (B4/B3/B2)",
"Land/Water (B8/B11/B4)",
"Color Infrared (B8/B4/B3)",
"Vegetation (B12/B11/B4)",
]
geemap.linked_maps(
rows=2,
cols=2,
height="300px",
center=[38.4151, 21.2712],
zoom=12,
ee_objects=[image],
vis_params=vis_params,
labels=labels,
label_position="topright",
)
m = geemap.Map(center=[40, -100], zoom=4)
collection = ee.ImageCollection("USGS/NLCD_RELEASES/2019_REL/NLCD").select("landcover")
vis_params = {"bands": ["landcover"]}
years = collection.aggregate_array("system:index").getInfo()
years
Create a timeseries inspector for NLCD. Note that ipyleaflet has a bug with the SplitControl. You can't pan the map, which should be resolved in a future ipyleaflet release.
m.ts_inspector(
left_ts=collection,
right_ts=collection,
left_names=years,
right_names=years,
left_vis=vis_params,
right_vis=vis_params,
width="80px",
)
m
Time slider¶
Note that this feature may not work properly with in the Colab environment. Restart Colab runtime if the time slider does not work.
Create a map for visualizing MODIS vegetation data.
m = geemap.Map()
collection = (
ee.ImageCollection("MODIS/MCD43A4_006_NDVI")
.filter(ee.Filter.date("2018-06-01", "2018-07-01"))
.select("NDVI")
)
vis_params = {
"min": 0.0,
"max": 1.0,
"palette": "ndvi",
}
m.add_time_slider(collection, vis_params, time_interval=2)
m
Create a map for visualizing weather data.
m = geemap.Map()
collection = (
ee.ImageCollection("NOAA/GFS0P25")
.filterDate("2018-12-22", "2018-12-23")
.limit(24)
.select("temperature_2m_above_ground")
)
vis_params = {
"min": -40.0,
"max": 35.0,
"palette": ["blue", "purple", "cyan", "green", "yellow", "red"],
}
labels = [str(n).zfill(2) + ":00" for n in range(0, 24)]
m.add_time_slider(collection, vis_params, labels=labels, time_interval=1, opacity=0.8)
m
Visualizing Sentinel-2 imagery
m = geemap.Map(center=[37.75, -122.45], zoom=12)
collection = (
ee.ImageCollection("COPERNICUS/S2_SR")
.filterBounds(ee.Geometry.Point([-122.45, 37.75]))
.filterMetadata("CLOUDY_PIXEL_PERCENTAGE", "less_than", 10)
)
vis_params = {"min": 0, "max": 4000, "bands": ["B8", "B4", "B3"]}
m.add_time_slider(collection, vis_params)
m
Exercise 2 - Creating land cover maps with a legend¶
Create a split map for visualizing NLCD land cover change in a selected US state between 2001 and 2019. Add the NLCD legend to the map. Relevant Earth Engine assets:
A sample map for visualizing NLCD land cover change in Texas is shown below:

Map = geemap.Map()
Map
roi = Map.user_roi
if roi is None:
roi = ee.Geometry.BBox(-18.6983, -36.1630, 52.2293, 38.1446)
Map.addLayer(roi)
Map.centerObject(roi)
timelapse = geemap.modis_ndvi_timelapse(
roi,
out_gif="ndvi.gif",
data="Terra",
band="NDVI",
start_date="2000-01-01",
end_date="2022-12-31",
frames_per_second=3,
title="MODIS NDVI Timelapse",
overlay_data="countries",
)
geemap.show_image(timelapse)
MODIS temperature data¶
Map = geemap.Map()
Map
roi = Map.user_roi
if roi is None:
roi = ee.Geometry.BBox(-171.21, -57.13, 177.53, 79.99)
Map.addLayer(roi)
Map.centerObject(roi)
timelapse = geemap.modis_ocean_color_timelapse(
satellite="Aqua",
start_date="2018-01-01",
end_date="2020-12-31",
roi=roi,
frequency="month",
out_gif="temperature.gif",
overlay_data="continents",
overlay_color="yellow",
overlay_opacity=0.5,
)
geemap.show_image(timelapse)
GOES timelapse¶
roi = ee.Geometry.BBox(167.1898, -28.5757, 202.6258, -12.4411)
start_date = "2022-01-15T03:00:00"
end_date = "2022-01-15T07:00:00"
data = "GOES-17"
scan = "full_disk"
timelapse = geemap.goes_timelapse(
roi, "goes.gif", start_date, end_date, data, scan, framesPerSecond=5
)
geemap.show_image(timelapse)
roi = ee.Geometry.BBox(-159.5954, 24.5178, -114.2438, 60.4088)
start_date = "2021-10-24T14:00:00"
end_date = "2021-10-25T01:00:00"
data = "GOES-17"
scan = "full_disk"
timelapse = geemap.goes_timelapse(
roi, "hurricane.gif", start_date, end_date, data, scan, framesPerSecond=5
)
geemap.show_image(timelapse)
roi = ee.Geometry.BBox(-121.0034, 36.8488, -117.9052, 39.0490)
start_date = "2020-09-05T15:00:00"
end_date = "2020-09-06T02:00:00"
data = "GOES-17"
scan = "full_disk"
timelapse = geemap.goes_fire_timelapse(
roi, "fire.gif", start_date, end_date, data, scan, framesPerSecond=5
)
geemap.show_image(timelapse)

{kind=link}
m = geemap.Map()
m.add_gui("timelapse")
m
Drought monitoring¶
In this section, we will explore drought datasets and anylyze drought patterns using Google Earth Engine. There are different types of droughts, including meteorological drought, agricultural drought, hydrological drought, and socioeconomic drought. Droughts can be monitored using various drought indices, such as the Palmer Drought Severity Index (PDSI), Standardized Precipitation Index (SPI), and Standardized Precipitation Evapotranspiration Index (SPEI).
Exploring drought datasets¶
There are several drought datasets available in the Earth Engine Community Catalog, including:
- United States Drought Monitor
- North American Drought Monitor (NADM)
- Canadian Drought Outlook
- United States Seasonal Drought Outlook
The Earth Engine Public Data Catalog also hosts several drought datasets, including:
- GRIDMET DROUGHT: CONUS Drought Indices
- SPEIbase: Standardised Precipitation-Evapotranspiration Index database
- KBDI: Keetch-Byram Drought Index
Let's explore the USDM dataset in the Earth Engine Community Catalog.
The U.S. Drought Monitor is a map released every Thursday, showing parts of the U.S. that are in drought. The map uses five classifications: abnormally dry (D0), showing areas that may be going into or are coming out of drought, and four levels of drought: moderate (D1), severe (D2), extreme (D3) and exceptional (D4).
The Drought Monitor has been a team effort since its inception in 1999, produced jointly by the National Drought Mitigation Center (NDMC) at the University of Nebraska-Lincoln, the National Oceanic and Atmospheric Administration (NOAA), and the U.S. Department of Agriculture (USDA). The NDMC hosts the web site of the drought monitor and the associated data, and provides the map and data to NOAA, USDA and other agencies. It is freely available at https://droughtmonitor.unl.edu.

To visualize the USDM data, open the USDM Explorer Web App and select any US county to view the weekly USDM data for that county.

m = geemap.Map(center=[40, -100], zoom=4)
collection = ee.ImageCollection("projects/sat-io/open-datasets/us-drought-monitor")
images = collection.filterDate("2023-01-01", "2024-01-01")
vis_params = {
"min": 0,
"max": 4,
"palette": ["#FFFF00", "#FCD37F", "#FFAA00", "#E60000", "#730000"],
}
m.add_layer(images.first(), vis_params, "US Drought Monitor")
legend_dict = {
"D0-Abnormally dry": "#FFFF00",
"D1-Moderate drought": "#FCD37F",
"D2-Severe drought": "#FFAA00",
"D3-Extreme drought": "#E60000",
"D4-Exceptional drought": "#730000",
}
m.add_legend(title="Drought Severity", legend_dict=legend_dict)
CONUS = ee.Geometry.BBox(-126.2109, 23.3221, -66.3574, 50.1206)
states = ee.FeatureCollection("TIGER/2018/States").filterBounds(CONUS)
counties = ee.FeatureCollection("TIGER/2018/Counties").filterBounds(CONUS)
style = {"color": "000000ff", "width": 2, "lineType": "solid", "fillColor": "00000000"}
m.add_layer(states.style(**style), {}, "US States")
m.add_layer(counties, {}, "US Counties", False)
m

m.add_time_slider(images, vis_params, time_interval=1, loop=True)
Creating drought timeseries animations¶
out_gif = "us_drought_monitor.gif"
geemap.create_timelapse(
images,
"2023-06-01",
"2024-01-01",
region=CONUS,
frequency="day",
vis_params=vis_params,
overlay_data="us_states",
overlay_color="white",
out_gif=out_gif,
)
geemap.show_image(out_gif)
Analyzing drought datasets¶
NASA reported July 2023 as Hottest Month on Record Ever Since 1880
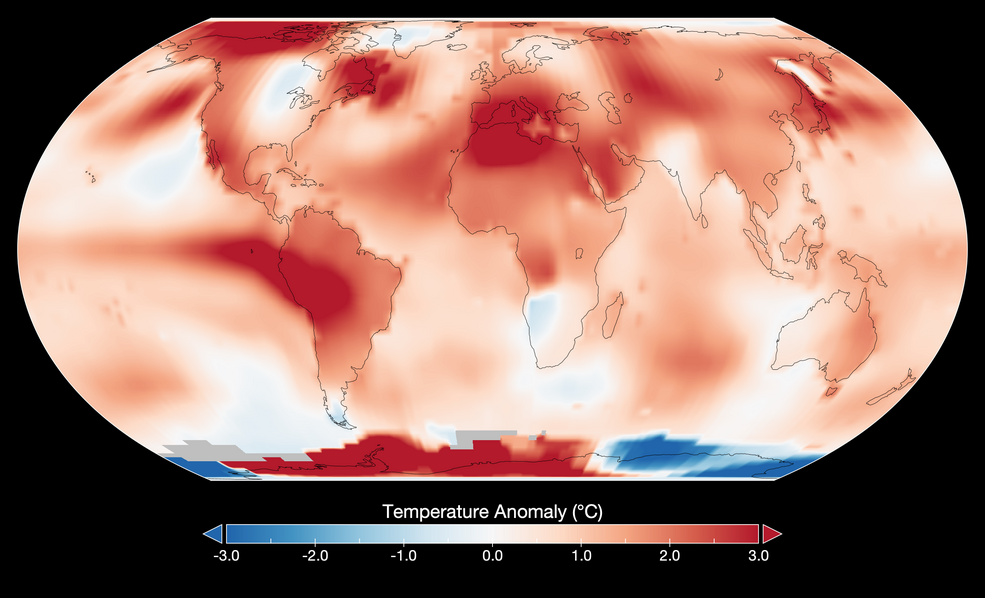
In this section, we will analyze drought patterns in the United States using the 4-km Gridded Surface Meteorological (GRIDMET) dataset, which contains drought indices such as the standardized precipitation index (SPI), the evaporative drought demand index (EDDI), the standardized precipitation evapotranspiration index (SPEI), the Palmer Drought Severity Index (PDSI) and Palmer Z Index (Z). The GRIDMET dataset is available from 1980 to the present. The dataset is updated every 5 days and has a spatial resolution of 4 km.
Let's filter the GRIDMET dataset to the year of 2023 and visualize the PDSI index for the month of July 2023.
start_date = "2023-07-01"
end_date = "2023-08-01"
pdsi_col = ee.ImageCollection("GRIDMET/DROUGHT").filterDate(start_date, end_date)
pdsi_col
Print out the GRIDMET dataset ids, which contain the date information in the YYYYMMDD format.
pdsi_col.aggregate_array("system:id")
Create a mean GRIDMET image for the month of July 2023.
pdsi_image = pdsi_col.filterDate(start_date, end_date).mean()
pdsi_image
Visualize the GRIDMET dataset for the month of July 2023.
m = geemap.Map(center=[40, -100], zoom=4)
# Make color options for standardized variables spi/spei/eddi
spi_vis = {"min": -2.5, "max": 2.5, "palette": "jet_r"}
# Make color options for Palmer variables psdi/z
drought_vis = {"min": -6, "max": 6, "palette": "coolwarm_r"}
pdsi = pdsi_image.select("pdsi")
z = pdsi_image.select("z")
spi30d = pdsi_image.select("spi30d")
spi90d = pdsi_image.select("spi90d")
spi180d = pdsi_image.select("spi180d")
spi1y = pdsi_image.select("spi1y")
m.add_layer(spi30d, spi_vis, "SPI-30d")
m.add_layer(spi90d, spi_vis, "SPI-90d")
m.add_layer(spi180d, spi_vis, "SPI-180d")
m.add_layer(spi1y, spi_vis, "SPI-1y")
m.add_layer(z, drought_vis, "Z-Index")
m.add_layer(pdsi, drought_vis, "PDSI")
m.add_colorbar(drought_vis, label="Drought Index")
m.add_colorbar(spi_vis, label="SPI Index")
CONUS = ee.Geometry.BBox(-126.2109, 23.3221, -66.3574, 50.1206)
states = ee.FeatureCollection("TIGER/2018/States").filterBounds(CONUS)
counties = ee.FeatureCollection("TIGER/2018/Counties").filterBounds(CONUS)
style = {"color": "000000ff", "width": 2, "lineType": "solid", "fillColor": "00000000"}
m.add_layer(states.style(**style), {}, "US States")
m.add_layer(counties, {}, "US Counties", False)
m

You can compare the GRIDMET PDSI map for July 2023 with the map of historical Palmer Drought Severity Index (PDSI) from NECI.

Let's select a county in the United States and extract the historical PDSI and SPI values. You can place a marker on the map to select a county. If no county is selected, the default county is set to the Clark County, Nevada, which includes the city of Las Vegas. We will extract the PDSI and SPI values for the selected county and create a time series chart.
if m.user_roi is not None:
point = m.user_rois
else:
point = ee.Geometry.Point(-115.04, 36.15)
roi = counties.filterBounds(point)
pdsi_col = (
ee.ImageCollection("GRIDMET/DROUGHT")
.select("pdsi")
.map(lambda img: img.clipToCollection(roi))
)
spi_col = (
ee.ImageCollection("GRIDMET/DROUGHT")
.select("spi30d")
.map(lambda img: img.clipToCollection(roi))
)
Create a monthly time series of PDSI for the selected county.
pdsi_ts = geemap.create_timeseries(
pdsi_col,
start_date="1980-01-01",
end_date="2024-07-01",
frequency="month",
reducer="mean",
)
pdsi_ts
Create a monthly time series of SPI for the selected county.
spi_ts = geemap.create_timeseries(
spi_col,
start_date="1980-01-01",
end_date="2024-07-01",
frequency="month",
reducer="mean",
)
spi_ts
Note that both the PDSI and SPI time series have 534 images, which represent the monthly values from January 1980 to June 2024. Let's select the month of March 2021 and visualize the PDSI and SPI values for the selected county.
m = geemap.Map()
start_date = "2021-03-01"
end_date = "2021-04-01"
pdsi_image = pdsi_col.filterDate(start_date, end_date).first()
spi_image = spi_col.filterDate(start_date, end_date).first()
m.add_layer(spi_image, drought_vis, "SPI")
m.add_layer(pdsi_image, drought_vis, "PDSI")
m.centerObject(roi, 8)
m.add_colorbar(drought_vis, label="Drought Index", layer_name="PDSI")
m.add_colorbar(spi_vis, label="SPI Index", layer_name="SPI")
m
Calculate the monthly mean PDSI for the selected county.
pdsi_csv = "pdsi_stats.csv"
geemap.zonal_stats(pdsi_ts, roi, pdsi_csv, stat_type="MEAN")
Calculate the monthly mean SPI for the selected county.
spi_csv = "spi_stats.csv"
geemap.zonal_stats(spi_ts, roi, spi_csv, stat_type="MEAN")
Read the PDSI values from the output csv and transform the data to a pandas DataFrame with a pdsi column.
df = geemap.csv_to_df(pdsi_csv)
pdsi_columns = [col for col in df.columns if "pdsi" in col.lower()]
df_pdsi = df[pdsi_columns]
df_pdsi = df_pdsi.T
df_pdsi.columns = ["pdsi"]
df_pdsi
Read the SPI values from the output csv and transform the data to a pandas DataFrame with a spi column.
df = geemap.csv_to_df(spi_csv)
spi_columns = [col for col in df.columns if "spi" in col.lower()]
df_spi = df[spi_columns]
df_spi = df_spi.T
df_spi.columns = ["spi"]
df_spi
Combine the PDSI and SPI data into a single DataFrame with pdsi, spi, and date columns.
df_pdsi["spi"] = df_spi["spi"].tolist()
dates = geemap.image_dates(pdsi_ts).getInfo()
df_pdsi["date"] = dates
df_pdsi.columns = ["pdsi", "spi", "date"]
df_pdsi
Create a bar chart for showing the historical PDSI values for the selected county.
geemap.bar_chart(df_pdsi, x="date", y=["pdsi"])

Create a bar chart for showing the historical SPI values for the selected county.
geemap.bar_chart(df_pdsi, x="date", y=["spi"])

Show the combined PDSI and SPI values in a single chart.
geemap.bar_chart(df_pdsi, x="date", y=["pdsi", "spi"])

Exercise - Analyzing drought data for a selected county¶
Select a county in the United States and extract the historical PDSI values. Create a time series chart to visualize the PDSI values for the selected county.
Analyzing and visualizing precipitation data¶
Exploring precipitation datasets¶
The Earth Engine Public Data Catalog hosts a lot of precipitation datasets, including:
- SPEIbase: Standardised Precipitation-Evapotranspiration Index database
- ERA5-Land Hourly - ECMWF Climate Reanalysis
- GPM: Monthly Global Precipitation Measurement
- Daymet V4: Daily Surface Weather and Climatological Summaries
- PRISM Daily Spatial Climate Dataset AN81d
- TRMM 3B42: 3-Hourly Precipitation Estimates
- CHIRPS Daily: Climate Hazards Group InfraRed Precipitation With Station Data
Calculating Standardized Precipitation Index (SPI)¶
The Standardized Precipitation Index (SPI) is a widely used index to characterize meteorological drought on a range of timescales. On short timescales, the SPI is closely related to soil moisture, while at longer timescales, the SPI can be related to groundwater and reservoir storage. The SPI can be compared across regions with markedly different climates. It quantifies observed precipitation as a standardized departure from a selected probability distribution function that models the raw precipitation data. The raw precipitation data are typically fitted to a gamma or a Pearson Type III distribution, and then transformed to a normal distribution. The SPI values can be interpreted as the number of standard deviations by which the observed anomaly deviates from the long-term mean. The SPI can be created for differing periods of 1-to-36 months, using monthly input data.
The SPI is calculated as follows:
SPI = (P-P*) / σp
where P = precipitation, p* = mean precipitation, and σp = standard deviation of precipitation.
In this section, we will use the PRISM Daily Spatial Climate Dataset to calculate the SPI. It has daily precipitation data from 1981 to present with a spatial resolution of 4 km. The dataset is based on the Parameter-elevation Regressions on Independent Slopes Model (PRISM) and is available from the Oregon State University PRISM Climate Group.
Let's filter the PRISM dataset to the month of July 2023 and calculate the total precipitation for the month.
m = geemap.Map(center=[40, -100], zoom=4)
dataset = (
ee.ImageCollection("OREGONSTATE/PRISM/AN81d")
.filter(ee.Filter.date("2023-07-01", "2023-08-01"))
.select("ppt")
)
ppt = dataset.sum()
ppt_vis = {
"min": 0.0,
"max": 200.0,
"palette": ["red", "yellow", "green", "cyan", "purple"],
}
CONUS = ee.Geometry.BBox(-126.2109, 23.3221, -66.3574, 50.1206)
states = ee.FeatureCollection("TIGER/2018/States").filterBounds(CONUS)
counties = ee.FeatureCollection("TIGER/2018/Counties").filterBounds(CONUS)
style = {"color": "000000ff", "width": 2, "lineType": "solid", "fillColor": "00000000"}
m.add_layer(ppt, ppt_vis, "Precipitation")
m.add_layer(states.style(**style), {}, "US States")
m.add_layer(counties, {}, "US Counties", False)
m.add_colorbar(ppt_vis, label="Precipitation (mm)")
m

Create monthly precipitation images from 1981 to 2024.
if m.user_roi is not None:
point = m.user_rois
else:
point = ee.Geometry.Point(-115.04, 36.15)
roi = counties.filterBounds(point)
dataset = ee.ImageCollection("OREGONSTATE/PRISM/AN81d").select("ppt")
prism_ts = geemap.create_timeseries(
dataset, "1981-01-01", "2024-07-01", frequency="month", reducer="sum"
)
Calculate the long-term mean precipitation and standard deviation of precipitation.
prism_ts_image = prism_ts.toBands()
ppt_mean = prism_ts_image.reduce(ee.Reducer.mean())
ppt_std = prism_ts_image.reduce(ee.Reducer.stdDev())
Calculate the SPI for the month of July 2023.
ppt_202307 = prism_ts.filterDate("2023-07-01", "2023-08-01").first()
spi_202307 = ppt_202307.subtract(ppt_mean).divide(ppt_std)
Visualize the SPI for the month of July 2023.
m = geemap.Map(center=[40, -100], zoom=4)
spi_vis = {"min": -2.5, "max": 2.5, "palette": "jet_r"}
m.add_layer(spi_202307, spi_vis, "SPI")
m.add_layer(states.style(**style), {}, "US States")
m.add_layer(counties, {}, "US Counties", False)
m.add_colorbar(spi_vis, label="SPI")
m

Exercise - Calculating SPI for a selected region¶
Select a region in the United States and calculate the SPI for the region using the PRISM dataset. Visualize the SPI for the region.