SciPy 2024¶
![]()
The notebook contains source code for the presentation at SciPy 2024 - Bridging the gap between Earth Engine and the Scientific Python Ecosystem.

Install packages¶
%pip install geemap geopandas dask-ee pydeck xee hypercoast pyvista mapclassify
Import libraries¶
import ee
import geemap
def in_colab_shell():
"""Tests if the code is being executed within Google Colab."""
import sys
if "google.colab" in sys.modules:
return True
else:
return False
Authenticate Earth Engine¶
EE_PROJECT_ID = "YOUR-PROJECT-ID" # Change the project ID to your own
ee.Authenticate()
ee.Initialize(project=EE_PROJECT_ID)
To Pandas DataFrame¶
We can convert an Earth Engine FeatureCollection to a Pandas DataFrame. First, let's add an ee.Image and a ee.FeatureCollection to the map.
m = geemap.Map(center=[40, -100], zoom=4)
dem = ee.Image("USGS/SRTMGL1_003")
dem_vis = {
"min": 0,
"max": 4000,
"palette": ["006633", "E5FFCC", "662A00", "D8D8D8", "F5F5F5"],
}
m.add_layer(dem, dem_vis, "SRTM DEM", True, 0.6)
states = ee.FeatureCollection("TIGER/2018/States").filterBounds(
ee.Geometry.BBox(-127, 23, -66, 50)
)
style = {"fillColor": "00000000"}
m.add_layer(states.style(**style), {}, "US States")
m
We can use zone statistics to calculate the mean elevation for each US state. The result can be returned as an ee.FeatureCollection.
dem_stats = geemap.zonal_stats(
dem, states, stats_type="MEAN", scale=1000, return_fc=True, verbose=False
)
Next, we can convert the ee.FeatureCollection to a Pandas DataFrame using the ee_to_df() function, which uses ee.data.computeFeatures() under the hood.
dem_df = geemap.ee_to_df(dem_stats)
dem_df.sort_values("mean", ascending=False).head()
Create a bar chart to show the mean elevation for each state.
geemap.bar_chart(
dem_df,
x="NAME",
y="mean",
x_label="State",
y_label="Mean Elevation (m)",
title="Average Elevation by State",
)
The zonal_stats() function above is a simple example of how to calculate zonal statistics based a vector data and a continuous raster image. For categorical raster images, we can use the zonal_stats_by_group() to calculate the total area or percentage of each category within each zone.
First, let's add a land cover image to the map.
m = geemap.Map(center=[40, -100], zoom=4)
dataset = ee.Image("USGS/NLCD_RELEASES/2021_REL/NLCD/2021")
landcover = dataset.select("landcover")
m.add_layer(landcover, {}, "NLCD 2021", True, 0.7)
states = ee.FeatureCollection("TIGER/2018/States").filterBounds(
ee.Geometry.BBox(-127, 23, -66, 50)
)
style = {"fillColor": "00000000"}
m.add_layer(states.style(**style), {}, "US States")
m.add_legend(title="NLCD Land Cover", builtin_legend="NLCD")
m
Calculate the total area of each land cover type for each state.
landcover_stats = geemap.zonal_stats_by_group(
landcover,
states,
stats_type="SUM",
scale=1000,
denominator=1e6, # Convert the unit to sq. km
decimal_places=2,
return_fc=True,
verbose=False,
)
Convert the result to a Pandas DataFrame.
landcover_df = geemap.ee_to_df(landcover_stats)
landcover_df.sort_values("Class_82", ascending=False).head()
Create a bar chart to show the total area of crop land for each state.
geemap.bar_chart(
landcover_df,
x="NAME",
y="Class_82",
x_label="State",
y_label="Crop Area (km2)",
title="Crop Area by State",
)
Create a pie chart to show each state's contribution to the total crop area of the contiguous United States.
geemap.pie_chart(
landcover_df,
"NAME",
"Class_82",
title="Crop Area by State",
height=600,
max_rows=30,
)
To GeoPandas GeoDataFrame¶
In addition to Pandas DataFrame, we can also convert an Earth Engine FeatureCollection to a GeoPandas GeoDataFrame. The ee_to_gdf() function is similar to the ee_to_df() function, but it returns a GeoPandas GeoDataFrame.
Let's convert the feature collection resulting from the elevation zonal statistics above to a GeoPandas GeoDataFrame.
dem_gdf = geemap.ee_to_gdf(dem_stats)
dem_gdf.head()
Create a choropleth map to show the mean elevation for each state.
if not in_colab_shell(): # This code block does not work well in Colab. Skip it
m = geemap.Map(center=[40, -100], zoom=4)
m.add_data(
dem_gdf,
column="mean",
cmap="terrain",
scheme="Quantiles",
k=10,
layer_name="Mean Elevation",
legend_title="Mean Elevation (m)",
)
m

Save the GeoDataFrame to a GeoJSON file.
dem_gdf.to_file("dem.geojson", driver="GeoJSON")
Visualize the GeoJSON file in 3D using the pydeck mapping backend.
import geemap.deck as geemap
if not in_colab_shell(): # This code block does not work well in Colab. Skip it
initial_view_state = {
"latitude": 40,
"longitude": -100,
"zoom": 3,
"pitch": 45,
"bearing": 10,
}
m = geemap.Map(initial_view_state=initial_view_state)
m.add_vector(
"dem.geojson",
extruded=True,
get_elevation="mean",
get_fill_color="[mean / 10, mean / 10, 0]",
elevation_scale=100,
)
m

To Dask DataFrame¶
Dask DataFrame helps you process large tabular data by parallelizing pandas, either on your laptop for larger-than-memory computing, or on a distributed cluster of computers.
The dask-ee Python package provides a bridge between Dask and Google Earth Engine. It allows you to use Dask to process Earth Engine vector data, which can be useful for large-scale data processing.
import dask_ee
import geemap
Let's use the Global Power Plant Database as an example.
fuels = [
"Coal",
"Oil",
"Gas",
"Hydro",
"Nuclear",
"Solar",
"Waste",
"Wind",
"Geothermal",
"Biomass",
]
colors = [
"000000",
"593704",
"BC80BD",
"0565A6",
"E31A1C",
"FF7F00",
"6A3D9A",
"5CA2D1",
"FDBF6F",
"229A00",
]
fc = ee.FeatureCollection("WRI/GPPD/power_plants").filter(
ee.Filter.inList("fuel1", fuels)
)
styled_fc = geemap.ee_vector_style(fc, column="fuel1", labels=fuels, color=colors)
m = geemap.Map(center=[40, -100], zoom=4)
m.add_layer(styled_fc, {}, "Power Plants")
m.add_legend(title="Power Plant Fuel Type", labels=fuels, colors=colors)
m
Convert the Earth Engine FeatureCollection to a Dask DataFrame using the read_ee() function.
df = dask_ee.read_ee("WRI/GPPD/power_plants")
df
Note that the Dask dataframe above only shows the structure of our feature collection - the columns and datatypes, but no actual data has been loaded yet. To load the data, we can use the compute() method.
df.compute().head()
Plot the total capacity of coal and wind plants in the United States, by year of commissioning.
(
df[df.comm_year.gt(1940) & df.country.eq("USA") & df.fuel1.isin(["Coal", "Wind"])]
.astype(
{"comm_year": int}
) # Year of plant operation, weighted by unit-capacity when data is available
.drop(columns=["geo"])
.groupby(["comm_year", "fuel1"])
.agg({"capacitymw": "sum"}) # Electrical generating capacity in megawatts
.reset_index()
.sort_values(by=["comm_year"])
.compute(scheduler="threads")
.pivot_table(index="comm_year", columns="fuel1", values="capacitymw", fill_value=0)
.plot()
)
To NumPy Array¶
To convert an Earth Engine Image to a NumPy array, we can use the ee_to_numpy() function, which uses ee.data.computePixels() under the hood.
Let's add a Landsat satellite image to the map.
m = geemap.Map()
image = ee.Image("LANDSAT/LC08/C02/T1_TOA/LC08_044034_20140318").select(
["B5", "B4", "B3"]
)
vis_params = {"min": 0, "max": 0.5, "gamma": [0.95, 1.1, 1]}
m.center_object(image, 8)
m.add_layer(image, vis_params, "Landsat")
region = ee.Geometry.BBox(-122.5955, 37.5339, -122.0982, 37.8252)
fc = ee.FeatureCollection(region)
style = {"color": "ffff00ff", "fillColor": "00000000"}
m.add_layer(fc.style(**style), {}, "ROI")
m
Convert a subset of the image to a NumPy array using the ee_to_numpy() function.
region = ee.Geometry.BBox(-122.5955, 37.5339, -122.0982, 37.8252)
rgb_img = geemap.ee_to_numpy(image, region=region)
print(rgb_img.shape)
Display the NumPy array using Matplotlib.
import matplotlib.pyplot as plt
rgb_img_test = (255 * ((rgb_img[:, :, 0:3]) + 0.2)).astype("uint8")
plt.imshow(rgb_img_test)
plt.show()
To Xarray Dataset¶
The Xee Python package provides a bridge between Xarray and Google Earth Engine. It allows you to convert Earth Engine Image objects to Xarray DataArray objects.
In this section, we will use the ERA5 hourly data to demonstrate how to convert an Earth Engine ImageCollection to an Xarray Dataset.
NASA reported that July 2023 as Hottest Month on Record Ever Since 1880 (source). Let's use Google Earth Engine to retrieve the temperature data for July 2023.
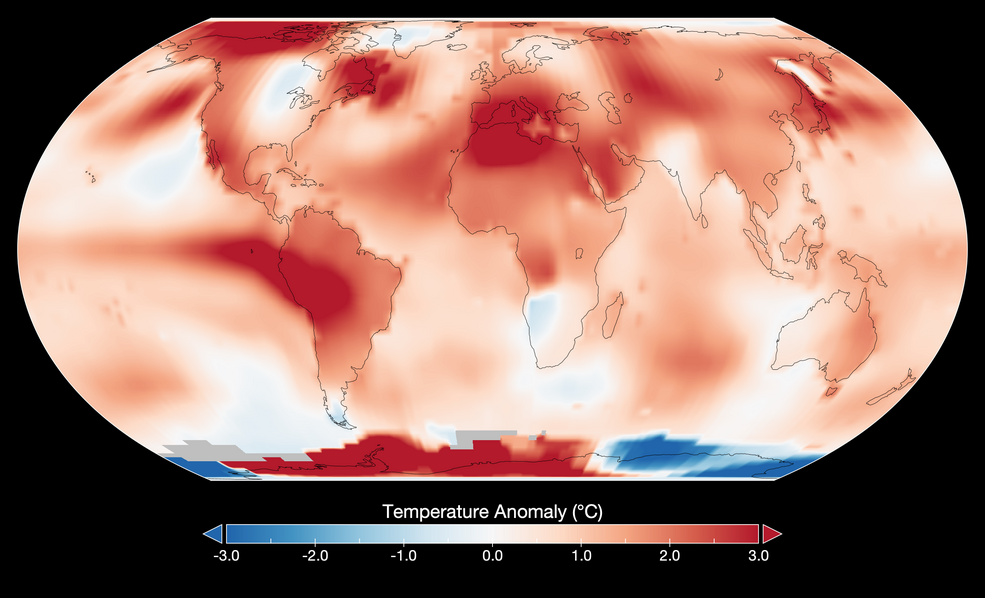
First, let's filter the ERA5 hourly data for July 2023 and select the temperature band.
m = geemap.Map(center=[40, -100], zoom=4)
dataset = (
ee.ImageCollection("ECMWF/ERA5_LAND/HOURLY")
.filter(ee.Filter.date("2023-07-01", "2023-08-01"))
.select("temperature_2m")
)
temp = dataset.mean()
temp_vis = {"min": 270, "max": 310, "palette": "coolwarm"}
m.add_layer(temp, temp_vis, "Temperature")
m.add_colorbar(temp_vis, label="Temperature (K)", layer_name="Temperature")
m
To convert the ImageCollection to an Xarray Dataset, let's initialize EE with the high-volume endpoint.
url = "https://earthengine-highvolume.googleapis.com"
ee.Initialize(url=url, project=EE_PROJECT_ID)
Now, we can convert the ImageCollection to an Xarray Dataset using the geemap.ee_to_xarray() function, which uses xee under the hood.
ds = geemap.ee_to_xarray(dataset, n_images=-1, ee_initialize=False)
ds
We can see that the xarray dataset has three dimensions: time, lon, and lat. The time dimension has 744 elements, which is the number of hours in the month of July 2023. The lon and lat dimensions are the number of pixels in the x and y directions, respectively. The dataset has one variable: temperature_2m.
da = ds["temperature_2m"]
Plot the first time step of the temperature data.
da.isel(time=1).plot(x="lon", y="lat", aspect=2, size=6, cmap="coolwarm")
Select the temperature data for July 1, 2023, 12:00:00 AM UTC and the horizontal profiles of the temperature data at different latitudes.
da.isel(time=1).sel(lat=[10, 30, 50, 70], method="nearest").plot(x="lon", hue="lat")
Calculate the mean temperature for July 2023.
da.mean(dim="time").plot(x="lon", y="lat", aspect=2, size=6, cmap="coolwarm")
Select daily images at 16:00:00 AM UTC (12 PM EST) in July 2023.
time_at_16 = da.sel(time=da["time"].dt.hour == 16)
time_at_16.shape
Calculate the mean temperature at 12 PM EST for July 2023.
time_at_16.mean(dim="time").plot(x="lon", y="lat", aspect=2, size=6, cmap="coolwarm")
Select monthly images at 16:00:00 AM UTC (12 PM EST) in 2023.
dataset = (
ee.ImageCollection("ECMWF/ERA5_LAND/HOURLY")
.filter(ee.Filter.date("2023-01-01", "2024-01-01"))
.filter(ee.Filter.calendarRange(1, 1, "day_of_month"))
.filter(ee.Filter.calendarRange(16, 16, "hour"))
.select("temperature_2m")
)
Convert the monthly images to an Xarray Dataset.
ds = geemap.ee_to_xarray(dataset, n_images=-1, ee_initialize=False)
ds
Select the temperature variable from the dataset.
monthly_da = ds["temperature_2m"]
Plot the temperature data for the first date of each month in 2023.
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=4, ncols=3, figsize=(20, 15))
axes = axes.flatten()
cbar_ax = fig.add_axes([0.92, 0.3, 0.01, 0.4])
for i, time in enumerate(monthly_da.time):
data = monthly_da.isel(time=i)
im = data.plot(ax=axes[i], x="lon", y="lat", cmap="coolwarm", add_colorbar=False)
axes[i].set_aspect(aspect="equal")
axes[i].set_title(str(time.values)[:10])
fig.colorbar(im, cax=cbar_ax)
plt.show()
3D visualization¶
The HyperCoast Python package provides some functions to visualize Xarray datasets in 3D using PyVista. Note that the PyVista 3D visualization backend does not work in Google Colab (source). However, you can uncomment the following two code blocks to enable static plotting in Google Colab.
# !apt-get install -qq xvfb libgl1-mesa-glx
# !pip install pyvista -qq
# import pyvista
# pyvista.set_jupyter_backend('static')
# pyvista.global_theme.notebook = True
# pyvista.start_xvfb()
import hypercoast
First, we need to transpose the Xarray Dataset to have the time dimension as the last dimension.
ds = ds.transpose("lat", "lon", "time")
ds
Visualize the monthly temperature data in 3D.
if not in_colab_shell(): # This code block does not work well in Colab. Skip it
p = hypercoast.image_cube(
ds,
variable="temperature_2m",
clim=(270, 310),
title="Temperature",
cmap="coolwarm",
grid_spacing=(1, 1, 3),
)
p.camera_position = [
(-479.09, -82.89, -444.45),
(89.5, 179.5, 16.5),
(0.58, 0.14, -0.80),
]
p.show()

Interactive thresholding of the temperature data.
if not in_colab_shell(): # This code block does not work well in Colab. Skip it
p = hypercoast.image_cube(
ds,
variable="temperature_2m",
clim=(270, 310),
title="Temperature",
cmap="coolwarm",
widget="threshold",
)
p.camera_position = [
(-479.09, -82.89, -444.45),
(89.5, 179.5, 16.5),
(0.58, 0.14, -0.80),
]
p.show()
